
1. 프로젝트 개요
대도시의 인구 과밀집으로 인한 안전성 문제가 날로 심각해지면서, 이를 분산 시키기 위한 여러
가지 정책과 인프라가 필요한 실정이다.

그러나 이에 관한 낮은 관심도와 사후처리와 같은 안일한 대처가 이태원 참사 같은 안타까운 안전 사고를 낳았다고 생각한다.
이번 글은 그 중에서도 시민들이 많이 이용하는 지하철이라는 테마에서 혼잡도에 따른 위험성을 알리고자 하는 프로젝트를 기획하였다.
물론 지하철 혼잡도를 제공해주는 모바일 앱이 존재하는 것으로 안다.
하지만 현재 서비스가 중지 되었거나 일부 호선의 열차만 제공되는 실정이다.
또한 6월 부터 CCTV를 이용한 승하차 집계 및 혼잡도 계산 사업을 진행 중이라고 서울교통공사에서 밝힌 바가 있으나 현재까지 추가적으로 들리는 소식이 없는 상태이다.

추가 안전 조치가 없는 공백 기간 동안, 지하철 혼잡도로 인한 인명사고를 예방하기 위해 머신러닝 회귀 분석을 통하여 혼잡도를 예측하고 위험시 경고하는 프로젝트를 진행하였다.

이번 프로젝트의 기대 효과로
- 위험 예방 및 안정성 향상
- 혼잡한 상황을 미리 알고 피할 수 있게 하는 편의성 향상
- 실시간 혼잡도에 대한 객관적 기준 확보로 정책 대책에 좋은 참고가 되며, 이에 따른 사회 시스템 편익 산출
등이 있다.
2. 준비 과정
6명의 팀원이 함께하여, 각자가 자신 있고 하고 싶은 분야 별로 나누어 진행하였다.

프로젝트는 약 한 달간 진행되었으며, 자세한 일정은 다음과 같다.

3. 프로젝트 개념
지하철 혼잡도란?

국토교통부 예규 ‘도시철도의 건설과 지원에 관한 기준’을 보면, 지하철 1량 당 정원을 160명으로 잡고 이를 혼잡도 100%로 두고 있다.
혼잡도가 100%라고 하면 만차 상태라고 인식하기 쉬운데, 실제 만차 상태는 혼잡도 150 %로서 이는 1량에 240명이 탑승했을 경우이다.
1량 당 재차인원 수에 따른 혼잡도 정도를 그림으로 표현하면 다음과 같다.

지금쯤 이런 생각을 하는 독자분들이 있을 지 모른다.
“혼잡도 별 상태를 알려주는 건 좋은데, 도대체 위험한 기준은 뭔가?”라고 말이다.
그에 대한 해답은 군중 밀집 연구 전문가인 Keith Still 교수로부터 얻을 수 있다.

군중밀집도(1 평방 미터 당 인원수)가 5이상일 시 군증들의 움직임이 예측 불가능하고 사고 위험성이 높다는 것이다.

- 더 자세한 내용을 알고 싶은 분들을 위한 링크
Standing Crowd Density | Prof. Dr. G. Keith Still
www.gkstill.com
그렇다면 서울시 지하철의 경우 어느 지점부터 위험성이 커지는 지 대략적으로 계산해보자.
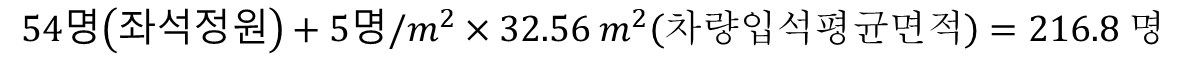
이를 혼잡도로 계산하면 135.5 %이다.
그런데 현재 서울시에서 나눈 지하철 혼잡도 단계를 살펴보자.

혼잡도 135.5 %의 경우 ‘주의’ 단계이지만, 추가 승차 제한의 경우 만차 기준인 ‘혼잡1’ 이상부터 시행된다.
따라서 사고 위험성이 있는 주의 단계에서도 미리 위험성을 알리고 다른 교통 수단을 이용하는 것을 장려하기 위해 혼잡도 예측 및 알림 서비스를 제공하는 것이 좋다고 판단하였다.
4. 진행과정 & 시행착오 트러블 슈팅
1. 데이터 수집 및 전처리
- 문제점
- 결측치
- 실시간 데이터 없음
- 역 이름이 변경된 곳 존재
- 원인
- 운행하지 않는 시간대의 인원
- 서울교통공사에서 혼잡도에 대한 실시간 데이터 미제공
- 개명된 역사 존재
- 해결 방법
- 결측치(NaN)를 0으로 처리
- 전체 평균 데이터에서 특정 월, 요일, 시간대 비율을 사용해 데이터 가공 및 혼잡도 유추
- 데이터를 최신 역이름으로 통일
2. 후보 모델 및 평가 지표 선정
- 문제점
- 데이터 전처리 및 변수 설정에 예상보다 시간이 더 소요되어 모델 학습을 진행하지 못함
- 원인
- 특성 변수 최종 미결정으로 인한 모델 후보 선정 어려움
- 해결 방법
- 일부 데이터만 이용한 임시 학습 데이터를 구성하여 모델 학습 진행
3. EDA (탐색적 데이터 분석)
- 문제점
- 기상에 대한 변수 (강수량) 제거로 모델 학습용 코드 변경 필요
- 원인
- EDA 도중 기상 데이터(강수량)가 혼잡도와 상관성이 없다는 것을 알게 됨.
- 해결 방법
- 기상에 대한 변수 (강수량) 제거 후, 나머지 수집 데이터로부터 독립 변수 설정 및 모델 학습용 코드 수정
4. 최종 변수 설정
- 문제점
- 예측에 사용되는 변수들이 충분하지 않다는 의견이 나옴
- 원인
- 범주형 변수들로만으로 종속변수가 충분히 설명될 수 있는 지에 대한 문제 제기
- 해결 방법
- 일단 범주형 변수만으로 학습 데이터 생성 및 모델 학습 후 평가. (R2_score 테스트 결과 범주형 변수들만으로 혼잡도 데이터에 대해 충분히 높은 설명력을 가짐을 확인)
5. 혼잡도 모델 학습 및 하이퍼파라미터 튜닝
- 문제점
- 하이퍼파라미터 튜닝시 모델 학습에 많은 시간 소요
- 다중공선성 문제
- 원인
- 튜닝 범위가 넓고, 무거운 모델을 최종 모델로 선정함 (XGBoost - XGBRegressor)
- 특성변수의 범주들 중 1개는 다른 나머지 범주들의 선형관계로 이루어져 강한 상관성을 이룸
- 해결 방법
- GridSearchCV에서 RamdomizedSearchCV로 변경하여 소요 시간 줄임
- 특성 변수 자유도를 n-1로 변경
6. 웹 서비스 로직
- 문제점
- 특정 노선에 대하여 혼잡도 예측 서비스 오류 발생
- 원인
- 2호선(순환형), 5호선(분기형) 같이 노선도가 일자형이 아닌 경우 혼잡도를 예측해주는 로직을 변경해줘야 했음
- 해결 방법
- 혼잡도 예측 함수 수정 및 웹 서비스 로직 변경 후 배포
7. 최종 완성
- 즉각적으로 혼잡도 예측을 할 수 있도록 최종 학습한 모델을 ‘.pkl’파일로 저장하고 이를 웹 서비스에 사용
- SQLite DB에는 노선정보와, 대쉬보드용 데이터만을 저장하여 DB의 부담을 줄임
- Django와 AWS를 통해 웹 배포 테스트도 진행하였음
5. 한계점 및 개선 사항, 최종 기대 효과

6. 프로젝트 로그
필자는 데이터 수집과 머신러닝 파트를 맡아 프로젝트를 진행하였다.
아래 접은 글은 일정 기간 동안 필자가 한 일을 간략히 정리한 내용이다.
09.01 ~ 09.08
한일: 프로젝트 기획, 데이터 수집
못한 일: 수집 데이터 정리
해야 할 일: 독립 변수 설정
09.11
한 일: 혼잡도 관련 추가 데이터 수집, 예상 독립 변수 설정
못한 일: 데이터 정제
해야 할 일: 데이터 전처리
09.12
한 일: 데이터 전처리
못한 일: 범주형 연속형 변수 여부 결정
해야 할 일: 후보 모델 선정
09.13
한 일: 범주형 변수로 결정, 머신러닝에 사용할 패키지 결정
못한 일: 학습 데이터 생성
해야 할 일: 평가 지표 결정
09.14
한 일: 후보 모델 선정, 평가 지표 결정
못한 일: 학습 데이터 생성
해야 할 일: 데이터 팀 지원
09.15
한 일: 간소화된 임시 학습 데이터 생성
못한 일: 모델 학습 코드 작성
해야 할 일: 모델 학습
09.18
한 일: 임시 학습 데이터셋으로 모델 학습 코드 구현 및, 학습
못한 일: 코드 정리 및 평가
해야 할 일: 코드 효율적으로 변경
09.19
한 일: 파이프라인을 활용해 효율적인 머신러닝 코드로 변경
못한 일: 하이퍼파라미터 튜닝 코드 작성
해야 할 일: 모델 최적화 방법 구현
09.20
한 일: 최종 데이터로 모델 학습 및 모델별 평가 지표 비교, 학습완료 모델 pkl 파일로 저장
못한 일: 최종 모델 1가지 선택, 특정 노선 (순환, 분기) 처리할 수 있는 코드 작성 및 웹 서비스 구현
해야 할 일: 팀원들과 의논하여 최종 모델 결정
09.21
한 일: 대쉬보드 시각화 내용 생성, 최종 모델 결정, 웹 서비스 구현 및 테스트
못한 일: 발표 PPT 작성
해야 할 일: 프로젝트 PPT 작성
09.22
한 일: 프로젝트 PPT 작성
못한 일: PPT 내용 간결하게 정리
해야 할 일: 정리 및 목차 부록 파트 정해서 분리
09.25
한 일: PPT 내용 축약 및 오타 수정, 부록 부분 정리 및 목차 다듬기
09.26 (최종발표)
7. 결과/산출물
GitHub 저장소에서 서비스 결과물에 대한 상세 정보를 확인할 수 있다.
GitHub - Jun-Gits/Transit_Insights: 지하철 혼잡도 예측 모델 개발
지하철 혼잡도 예측 모델 개발. Contribute to Jun-Gits/Transit_Insights development by creating an account on GitHub.
github.com