
이번에는 지난 시간에 이어 Selenium을 활용하여 크롤링 코드를 만들어 보자.
가상환경에서 jupyter lab을 실행하고, ipynb을 작성한다.
필자는 지난 시간에 만들어 준 crawling 폴더에서 실습을 진행한다.
Web Crawling (with Selenium) (1)
Selenium은 간단하게 일회성으로 웹크롤링하기 좋은 패키지이다. (다회성이 아닌 이유: 코드 유지-보수가 힘들기 때문) 이번 시간에는 Webdriver manager와 Selenium을 활용해 웹사이트에 접속하는 것을
sim-ds.tistory.com
1. 구글 이미지 다운로드
‘Selenium.ipynb’ 파일을 생성한 뒤, 먼저 아래 코드를 작성한다.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
URL='https://www.google.co.kr/imghp'
driver.get(url=URL)
# 검색
elem = driver.find_element(By.CSS_SELECTOR, "body > div.L3eUgb > div.o3j99.ikrT4e.om7nvf > form > div:nth-child(1) > div.A8SBwf > div.RNNXgb > div > div.a4bIc > textarea.gLFyf")
elem.send_keys("보라카이")
elem.send_keys(Keys.RETURN)
# 페이지 스크롤
elem = driver.find_element(By.TAG_NAME, "body")
for i in range(60):
elem.send_keys(Keys.PAGE_DOWN)
time.sleep(0.1)
# 스크롤이 끝까지 내려갔을 때 결과 더보기 버튼 클릭
try:
driver.find_element(By.CSS_SELECTOR, "#islmp > div > div > div > div.gBPM8 > div.qvfT1 > div.YstHxe > input").click()
for i in range(60):
elem.send_keys(Keys.PAGE_DOWN)
time.sleep(0.1)
except:
pass
# 이미지 src 정보 받기 & 찾은 이미지 개수 표시
links=[]
images = driver.find_elements(By.CSS_SELECTOR, "#islrg > div.islrc > div > a.wXeWr.islib.nfEiy > div.bRMDJf.islir > img")
for image in images:
if image.get_attribute('src') is not None:
links.append(image.get_attribute('src'))
print(' 찾은 이미지 개수:',len(links))해당 코드의 진행 순서는 다음과 같다.
elem 객체에 HTML 태그 또는 CSS 문법을 할당하여 웹페이지의 해당 구역에 접근하는 방식을 사용한다.
- ‘구글이미지검색’에서 ‘보라카이’ 키워드를 검색
- 검색 결과 페이지에서 스크롤하여 드라이버에 이미지를 로딩함
- 이미지의 src 정보를 받음. (매크로 차단 방지를 위해 0.1초의 텀을 준다.)
- 다운로드 할 이미지의 개수를 사용자에게 표시해줌.
코드를 실행하면 브라우저가 열리며 크롤링을 시작한다.
필자의 실행 결과 찾은 이미지 개수는 42개이다.

- CSS_SELECTOR로 필요 element 가져오는 법
구글 크롬 브라우저의 개발자 모드를 사용하면 element를 쉽게 가져올 수 있다.
1. 페이지 빈 공간 마우스 우클릭 > 검사 (단축키: F12)
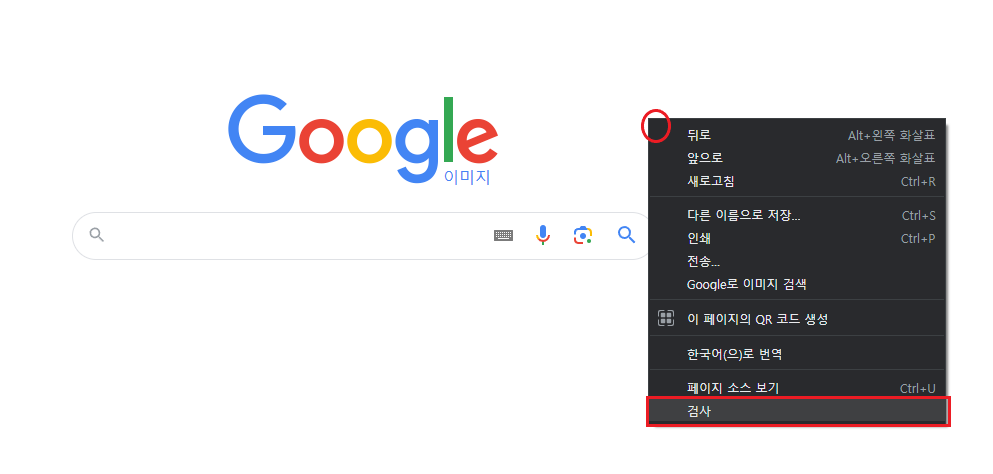
2. 마우스로 element를 선택하는 기능 사용 (단축키: Crtl + Shift + C)

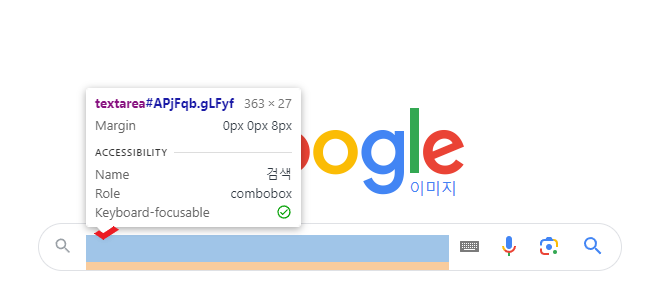
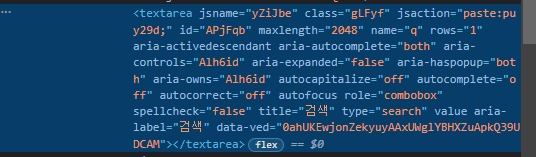
3. 접근하고자 하는 element 클릭하면 개발자 tool에서 강조됨
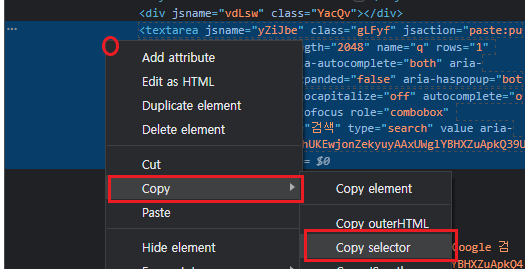
4. 강조된 부분에서 마우스 우클릭 > Copy > Copy selector
5. 복사된 텍스트를 붙여 넣기하면…
#APjFqb (어라?… 이게 아닌데)
가끔 element의 id만 복사될 때가 있다. 그럴 때에는 당황하지 말고 개발자 tool 밑 부분을 찾아보자.
(제대로 나올 경우 복붙해서 그대로 쓰면 된다.)

body > div.L3eUgb > div.o3j99.ikrT4e.om7nvf > form > div:nth-child(1) > div.A8SBwf > div.RNNXgb > div > div.a4bIc > textarea.gLFyf귀찮지만 위 내용을 직접 타이핑해주면 된다.
다음 코드 탭으로 넘어가서 이미지를 다운로드 하는 코드를 작성해준다.
import urllib.request
for k, i in enumerate(links):
url = i
urllib.request.urlretrieve(url, ".\\사진다운로드\\"+str(k)+".jpg")
print('다운로드 완료하였습니다.')
driver.quit()
실습 중인 폴더에서 사진다운로드 폴더가 생긴 것을 확인. 생기지 않았으면 jupyter lab을 새로고침 해준다.

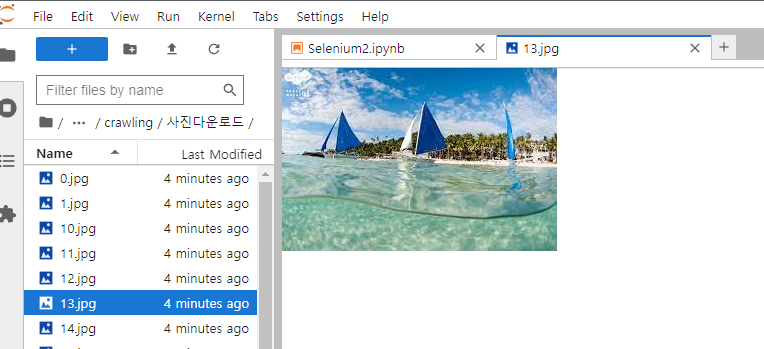
해당 폴더에 이미지가 다운로드 된 것을 확인한다.
2. nate.com 실시간 검색어 순위
이번에는 실시간 검색어 순위를 크롤링 하는 코드를 작성해보자.
다음 코드 탭에서 아래 코드를 작성해준다.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
nate_list_1st = []
nate_list_2nd = []
for i in range(2):
URL='https://www.nate.com'
driver.get(url=URL)
rank_results = driver.find_elements(By.CSS_SELECTOR,'#olLiveIssueKeyword > li > span.num_rank')
nate_results = driver.find_elements(By.CSS_SELECTOR,'#olLiveIssueKeyword > li > a > span.txt_rank')
for rank, keyword in zip(rank_results, nate_results):
if i == 0: # 첫번째 화면
nate_list_1st.append(f'{rank.text}_{keyword.text}')
elif i == 1: # 두번째 화면
nate_list_2nd.append(f'{rank.text}_{keyword.text}')
time.sleep(10)
driver.refresh() # driver 재시동
result = nate_list_1st + nate_list_2nd
print(result)
driver.quit()
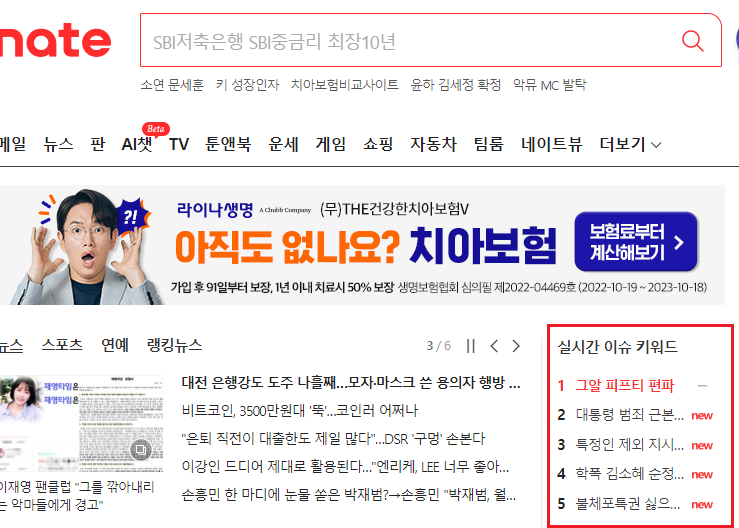
nate의 경우 실시간 이슈 키워드를 1~5위, 6~10위로 나누어 시간차를 두고 사용자에게 보여준다.
따라서 반복문을 통해 첫번째 순위 키워드 목록을 받고 새로고침을 통하여 다음 순위 목록을 받는 형식으로 코드를 작성하였다.
- 키워드에 접근하는 방식은 마찬가지로 CSS_SELECTOR를 사용하였다.
- 키워드를 받은 후 결과를 사용자에게 보여주고, 드라이버를 종료해준다.

코드 실행 결과: 실시간 이슈 키워드 목록 출력
'# Coding > Web Crawling' 카테고리의 다른 글
| Web Crawling (with Scrapy) (0) | 2023.08.21 |
|---|---|
| Web Crawling (with BeautifulSoup) (0) | 2023.08.21 |
| Web Crawling (with Selenium) (1) (0) | 2023.08.18 |