
이번 시간엔 Selenium대신 BeautifulSoup를 활용하여 크롤링을 진행해보자.
- 이전 글- Selenium을 활용한 웹 크롤링
Web Crawling (with Selenium) (2)
이번에는 지난 시간에 이어 Selenium을 활용하여 크롤링 코드를 만들어 보자. 가상환경에서 jupyter lab을 실행하고, ipynb을 작성한다. 필자는 지난 시간에 만들어 준 crawling 폴더에서 실습을 진행한다
sim-ds.tistory.com
BeautifulSoup는 웹에서 응답하는 여러 방식들 (HTML, XML, JSON 등)을 수프객체로 만들어서 추출하기 쉽게 만들어주는 라이브러리이다.
0. 패키지 설치
저번 시간에 이어 Python 가상환경에 필요한 추가 패키지를 설치해주자
requirements.txt 업데이트
webdriver-manager
pandas
requests
beautifulsoup4
fake_useragent
openpyxl
(venv) $ pip install -r requirements.txt가상환경에서 설치!
설치 후, BeautifulSoup가 어떻게 작동하는지 간단한 예시를 살펴보자.
1. Beautifulsoup 작동 방식
저번 시간에 이어 crawling 폴더에서 실습을 진행한다.
html 폴더생성 후 그 안에 index.html 파일 생성
( crawling > html > index.html)
# -*- coding:utf-8 -*-
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>크롤링 웹페이지</title>
</head>
<body>
<div class="fake">
<p>여기는 크롤링 하지 마세요!</p>
</div>
<div class="true">
<p>여기는 크롤링 해주세요1</p>
<p>여기는 크롤링 해주세요2</p>
<p>여기는 크롤링 해주세요3</p>
</div>
</body>
</html>HTML 파일 위와 같이 작성
BeautifulSoup를 활용하여 텍스트 부분만 추출하는 것을 진행해보자.
crawling 폴더에서 ‘BeautifulSoup1.py’ 파일을 만든 뒤, 다음 코드를 생성해준다.
from bs4 import BeautifulSoup
def main():
# index.html을 불러와서 BeautifulSoup 객체로 초기화
# 웹에서 응답을 할 때, HTML, XML, JSON 등 여러가지 방식들 존재
# HTML
soup = BeautifulSoup(open("html/index.html", encoding="utf-8"), "html.parser")
print(soup)
print(type(soup), "\n\n")
print(soup.title.string, "\n\n")
print(soup.find("p").get_text(), "\n\n")
true_str = soup.find('div', class_ = 'true').find_all('p')
print(true_str[0].get_text(), "\n")
print(true_str[1].get_text(), "\n")
print(true_str[2].get_text(), "\n")
if __name__ == "__main__":
main()
(venv) $ python BeautifulSoup1.py터미널에서 Python 파일 실행
- 코드 실행 결과는 다음과 같다.

먼저 index.html 파일을 수프 객체로 변경하여 텍스트 객체로 저장되는 것을 확인 할 수 있다.

그 다음은 title.string으로 html 파일의 title 부분의 내용을 가져올 수 있다.

get_text를 사용하여 텍스트 내용 부분만 가져 올 수 있다.
위 내용은 크롤링 시 p-tag로 접근하였는데 원하지 않는 부분이 출력된 경우이다.
“여기는 크롤링 해주세요” 부분도 분명 p-tag로 표시되어 있지만
“여기는 크롤링 하지 마세요!” 부분도 p-tag로 되어있기 때문에
find method로 접근하려면 상위 개념인 div를 활용해야한다.

게다가 “여기는 크롤링 해주세요”는 총 3번 등장하기 때문에, div-class로 접근한 다음, p-tag에 대해 find_all method를 적용해주면 된다.
find_all는 적용 시 해당하는 내용을 리스트로 반환해준다.
2. 뉴스 기사 타이틀 크롤링
본격적으로 BeautifulSoup를 사용해 웹 크롤링을 해보자.
‘BeautifulSoup2.py’ 파일 생성 및 다음 코드 작성
# 뉴스 기사 제목 타이틀 가져오기
import requests
from bs4 import BeautifulSoup
def crawler(soup):
div = soup.find("div", class_ = "list_body")
result = []
for a in div.find_all("a"): # find_all 반환값 = 리스트
# print(a.get_text())
result.append(a.get_text())
return result
def main():
# 크롤링 봇 차단 방지
custom_header = {
'referer' : 'https://www.naver.com/',
'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
url = "https://news.naver.com/main/list.nhn?mode=LPOD&mid=sec&sid1=001&sid2=140&oid=001&isYeonhapFlash=Y"
req = requests.get(url, headers = custom_header)
print(req.status_code, "\n\n") # 정상 접속 확인
soup = BeautifulSoup(req.text, "html.parser")
news_title = crawler(soup)
print(news_title)
if __name__ == "__main__":
main()기사 제목 부분의 텍스트를 반환해주는 crwaler 함수를 정의해준다.
main 함수에서는 뉴스 사이트의 url에 접속해 request의 응답을 받아오고 , 수프 객체로 바꿔준 다음 crwaler 함수를 호출해주는 식으로 진행한다.
custon_header의 경우 사용자가 브라우저를 통해 접속하는 것처럼 정보를 담아 request 보내는 데에 사용된다.
(venv) $ python BeautifulSoup2.py코드 작성이 완료 되면 터미널에서 ‘BeautifulSoup2.py’ 를 실행해준다.
- 코드 실행 결과는 다음과 같다.
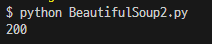
req.status_code: 200 (정상 접속 상태)

뉴스 타이틀 목록
3. 벅스 차트 Top 100 크롤링
이번에는 벅스 음원 사이트에서 Top 100 차트의 곡 목록을 크롤링으로 뽑아서 csv 파일로 저장까지 해보도록 하자.
‘bugs_songChart.py’ 파일을 생성하고 다음 코드를 작성한다.
### 벅스 차트 실시간 Top 100 크롤링
import requests
from bs4 import BeautifulSoup
import pandas as pd
def creatDF(result_list):
result_df = pd.DataFrame({"title" : result_list})
return result_df
def crawler(soup):
tbody = soup.find("tbody")
result = []
for p in tbody.find_all("p", class_ = "title"): # find_all 반환값 형태는 리스트다!
result.append(p.get_text().replace('\n', ''))
return result
def main():
custom_header = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36'
}
url = "https://music.bugs.co.kr/chart"
req = requests.get(url, headers = custom_header)
soup = BeautifulSoup(req.text, "html.parser")
result = crawler(soup)
df = creatDF(result)
print(df)
df.to_csv("result.csv", index=False)
if __name__ == "__main__":
main()- creatDF
“title” 이라는 컬럼에 크롤링한 결과 리스트를 담아 데이터 프레임을 생성해준다.
- crawler
수프 객체에서 곡 이름 부분을 크롤링하여 리스트로 반환해주는 역할을 해준다.
- main
custon_header를 지정해 크롤링 매크로가 아닌 브라우저에서 접속하는 것처럼 위장
벅스 차트 url에 접속해 request의 응답을 받아 html 문서를 soup에 저장한다.
crawler 함수를 호출해 차트의 곡 이름을 크롤링
creatDF 함수를 호출해 크롤링 목록을 데이터프레임으로 변환
데이터프레임 내용을 터미널에 출력
pandas에서 데이터프레임을 csv 파일로 변경해주는 to_csv 사용
(venv) $ python bugs_songChart.pyPython 파일 실행
코드 실행결과는 다음과 같다.


4. 주가 트렌드 크롤링
마지막으로 네이버 주식에서 주가 트렌드 정보를 크롤링해보자.
‘stock_trend.py’ 파일을 생성하고 다음 코드를 작성한다.
# 주가 트렌드 크롤링
import requests
import pandas as pd
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
def crawler(url, com_code):
url = url + com_code
ua = UserAgent()
headers = { 'user-agent': ua.ie }
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
return url, soup
def getLastPage(soup):
last_page = int(soup.select_one('td.pgRR').a['href'].split('=')[-1])
return last_page
def getData(url, page):
df = None
count = 0
for page in range(1, page + 1):
headers = { 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36' }
req = requests.get(f'{url}&page={page}', headers=headers)
# 테이블이 있는 html은 Soup 객체 생성 없이 pandas로도 쉽게 접근이 가능하다.
# read_html 메서드를 활용한다.
df = pd.concat([df, pd.read_html(req.text, encoding = "euc-kr")[0]], ignore_index=True)
if count > 10:
break
count += 1
data = df.dropna().reset_index(drop=True)
return data
def main():
url = "https://finance.naver.com/item/sise_day.nhn?code="
com_code = '005930' # 삼성전자 종목 코드
com_url, soup = crawler(url, com_code)
last_page = getLastPage(soup)
result = getData(com_url, last_page)
print(result)
result.to_excel("stock_trend.xlsx", index=False)
if __name__ == "__main__":
main()
- crwaler
주식사이트와 종목코드를 받아 크롤링할 url 주소를 만들어 준다.
fake_useragent의 Useragent를 사용하여 헤더 내용을 채워준다.
url에 접속하여 request의 응답을 받아 response에 저장
response의 컨텐츠를 html.parser를 써서 soup 객체로 변환
url 주소와 soup를 반환해줌
- getLastPage
soup 객체를 받아 html의 맨끝 페이지 번호를 추출하고 반환해줌
- getData
해당 주식종목을 보여주는 사이트에서 1페이지 부터 원하는 페이지까지 반복문을 활용해 페이지로 부터 request의 응답을 받음
html의 테이블 부분을 read_html method를 통해 인코딩해준 뒤, concat을 통해 데이터프레임으로 저장해준다.
여기서는 코드 실행 시간이 길어지는 것을 방지하고자 어떤 페이지 번호를 받아도 10 페이지까지만 읽어 오도록 if-break 구문을 사용하였다.
데이터프레임의 인덱스를 초기화해준 뒤 반환해줌
- main
url에 네이버 증권 사이트를 할당해줌
com_code에 조회하고 싶은 주식 종목 코드를 넣어준다. (여기서는 삼성전자를 사용)
crawler 함수 호출
getLastPage 함수 호출
getData를 통해 주가 정보 데이터 프레임을 result로 저장
터미널에 result 출력 및 excel 파일로 저장
(venv) $ python stock_trend.py코드 실행


'# Coding > Web Crawling' 카테고리의 다른 글
| Web Crawling (with Scrapy) (0) | 2023.08.21 |
|---|---|
| Web Crawling (with Selenium) (2) (0) | 2023.08.21 |
| Web Crawling (with Selenium) (1) (0) | 2023.08.18 |