
이번 시간에는 Scrapy 프레임 워크를 사용하여 웹 크롤링을 해보자.
Scrapy 프레임 워크는 Selenium이나 BeautifulSoup같이 method를 호출해서 접근하는 방식을 쓰는 라이브러리와 달리, Django 처럼 템플릿이나 패턴 규칙에 따라 파일을 작성 후 실행하는 방식으로 진행된다.
0. 환경 설정
임의의 폴더 생성 및 VS Code로 열기 > 터미널 실행
$ virtualenv venv가상환경 생성
$ source venv/Scripts/activate가상환경 실행
(venv) $ pip install scrapy가상환경에 Scrapy 설치
1. 프로젝트 실행
(venv) $ scrapy startproject Scrapy_tutorial‘Scrapy_tutorial’ 프로젝트 생성
(venv) $ cd Scrapy_tutorial/프로젝트 폴더로 이동
(venv) $ scrapyscrapy 버전 및 명령어 확인
Scrapy 2.10.0 - active project: Scrapy_tutorial
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
check Check spider contracts
crawl Run a spider
edit Edit spider
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
list List available spiders
parse Parse URL (using its spider) and print the results
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
세계 인구수 정보를 보여주는 사이트에서 Scrapy를 통한 크롤링을 진행해보자.

사이트 주소: https://www.worldometers.info/world-population/population-by-country/
(venv) $ scrapy genspider worldometer www.worldometers.info/world-population/population-by-country‘worldometer’ 라는 이름으로 spiders 폴더에 Python 파일 생성

(venv) $ cd Scrapy_tutorial/spiders/경로 변경: Scrapy_tutorial > Scrapy_tutorial > spiders
spiders > worldometer.py 파일 작성
다음 코드를 작성해준다.
import scrapy
class WorldometerSpider(scrapy.Spider):
name = "worldometer"
allowed_domains = ["www.worldometers.info/"]
start_urls = ["http://www.worldometers.info/world-population/population-by-country"]
def parse(self, response):
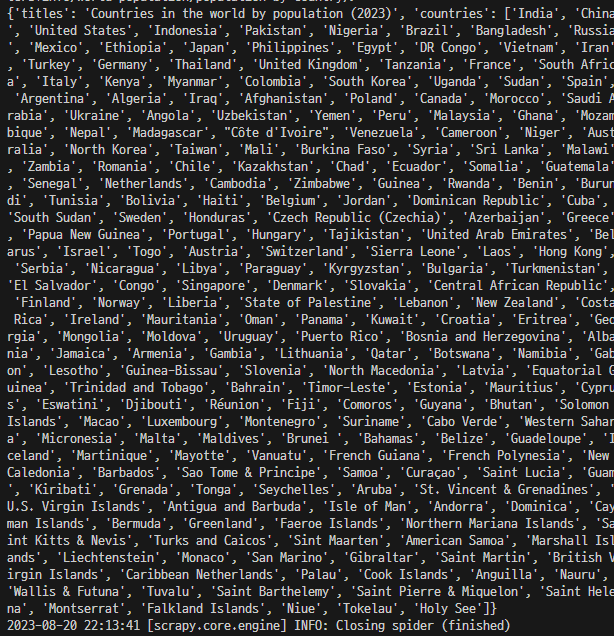
title = response.xpath('//h1/text()').get()
countries = response.xpath('//td/a/text()').getall()
yield {
'titles' : title,
'countries' : countries,
}‘worldometer.py’가 있는 경로에서
(venv) $ scrapy crawl worldometer크롤링 명령어 실행
2. 사이트의 링크 부분 가져오기
다양한 국가의 인구 정보 트렌드에 접근하기 위해 사이트에서 링크를 가져오는 코드를 작성해 보자
spiders > worldometer.py 파일 수정
import scrapy
class WorldometerSpider(scrapy.Spider):
name = "worldometer"
allowed_domains = ["www.worldometers.info/"]
start_urls = ["http://www.worldometers.info/world-population/population-by-country"]
def parse(self, response):
# step02
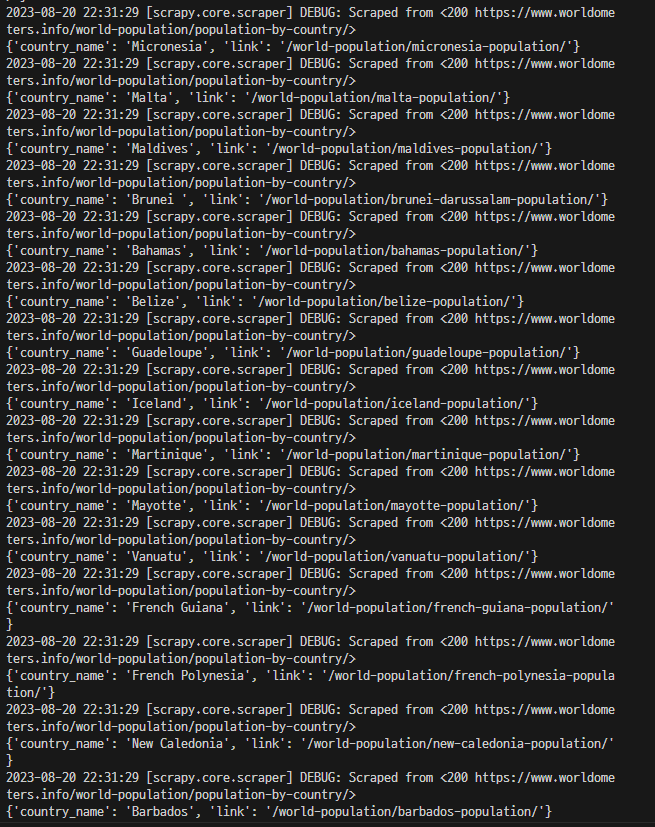
countries = response.xpath('//td/a')
for country in countries:
country_name = country.xpath(".//text()").get()
link = country.xpath(".//@href").get()
yield {
'country_name' : country_name,
'link' : link,
}파일과 같은 경로에서 다시 다음 명령어를 실행해준다.
(venv) $ scrapy crawl worldometer
3. 링크에 접근 후 각국의 연도별 인구수 데이터 추출
각 국가의 인구 정보 트렌드 데이터를 추출해 json 형태로 출력해보자
spiders > worldometer.py 파일 수정
import scrapy
class WorldometersSpider(scrapy.Spider):
name = 'worldometer'
allowed_domains = ['www.worldometers.info']
start_urls = ['https://www.worldometers.info/world-population/population-by-country/']
def parse(self, response):
# a 요소 확인
countries = response.xpath('//td/a')
# 반복문
for country in countries:
country_name = country.xpath(".//text()").get()
link = country.xpath(".//@href").get()
# 상대경로로 링크 접근
yield response.follow(url=link, callback=self.parse_country, meta={'country':country_name})
# Getting data inside the "link" website
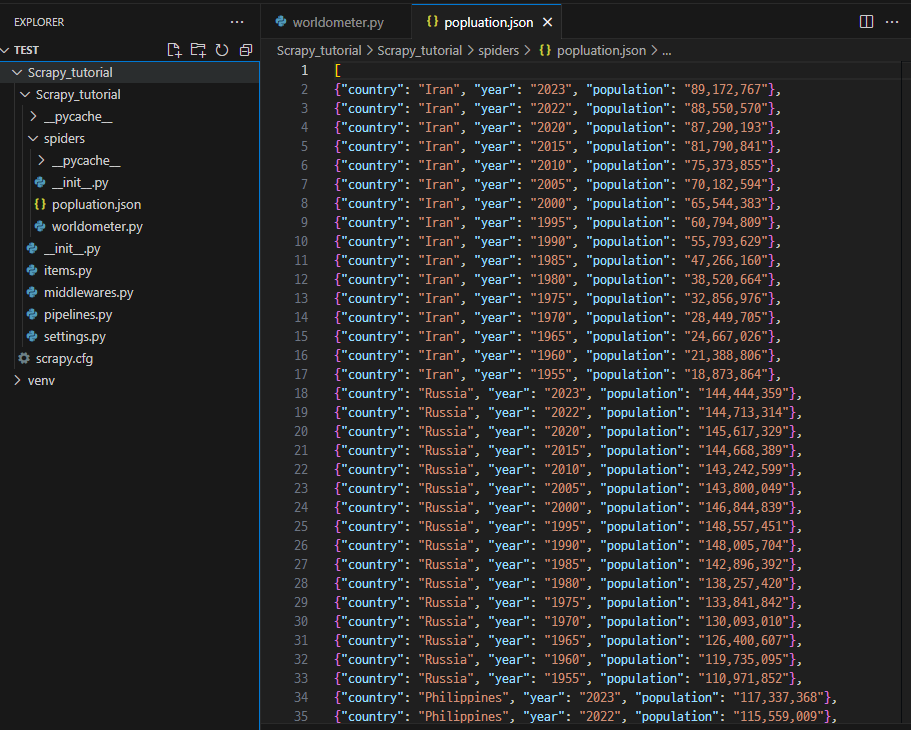
def parse_country(self, response):
country = response.request.meta['country']
rows = response.xpath("(//table[contains(@class,'table')])[1]/tbody/tr")
for row in rows:
year = row.xpath(".//td[1]/text()").get()
population = row.xpath(".//td[2]/strong/text()").get()
# Return data extracted
yield {
'country':country,
'year': year,
'population':population,
}각 국가마다 차례로 인구 트렌드 링크를 타고 이동한 뒤, 연도별 인구수 정보를 받아오는 반복문 코드를 작성하였다.
(HTML 태그나 xpath는 크롬브라우저의 개발자 모드(F12)를 이용하여 찾음)
scrapy crawl worldometer -o popluation.json이번에는 파일을 실행하고 json 파일로 내보내는 명령어를 실행해준다.
'# Coding > Web Crawling' 카테고리의 다른 글
| Web Crawling (with BeautifulSoup) (0) | 2023.08.21 |
|---|---|
| Web Crawling (with Selenium) (2) (0) | 2023.08.21 |
| Web Crawling (with Selenium) (1) (0) | 2023.08.18 |